TG Leads Parser
Парсер сообщений из групп по ЖК в Санкт-Петербурге с rule-based скорингом для выявления потенциальных покупателей.
Проблема → Решение
Потенциальные покупатели недвижимости часто задают вопросы в чатах жилых комплексов: про ипотеку, планировки, сроки сдачи. Эти сообщения — сигналы о намерении купить. Но чатов много, они шумные, и вручную отслеживать их нереально.
Решение: автоматический сбор сообщений из публичных групп, нормализация данных, rule-based скоринг по признакам намерения и экспорт кандидатов для дальнейшей работы.
Функциональность v1
Архитектура пайплайна
Parser execution & data pipeline
Консольный запуск парсера: backfill сообщений, дедупликация, первичная фильтрация и подсчёт сигналов.
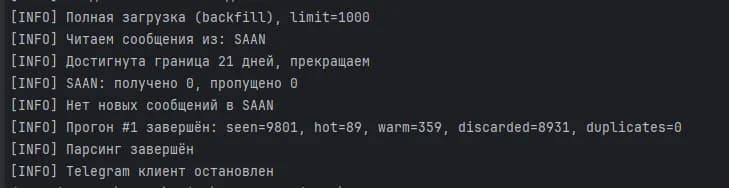
seen=9801 · hot=89 · warm=359 · discarded=8931
Rule-based lead scoring
Каждое сообщение классифицируется по типу намерения, финансовым триггерам и наличию вопроса. Итог — числовой сигнал для отбора.
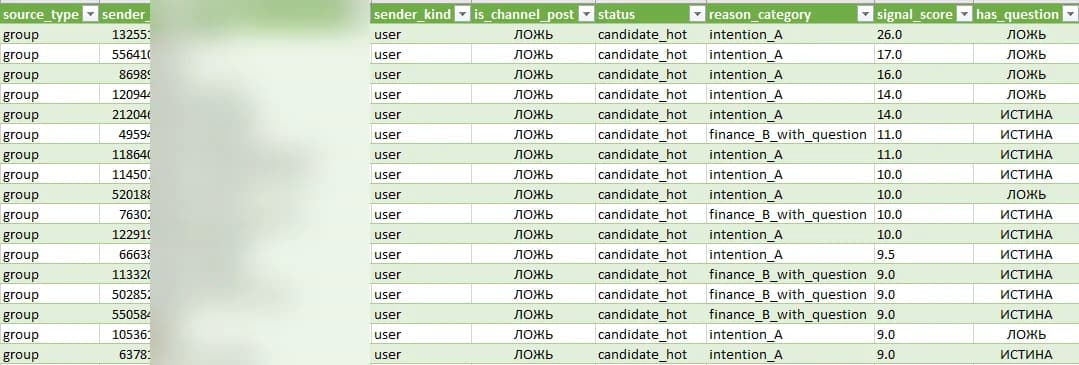
Ключевые поля данных
Идентификация
tg_chat_id · tg_message_id · message_date_utc · message_link
Источник
chat · jk · source_type · sender_kind · is_channel_post
Скоринг
signal_score · status · reason_category · has_question
Контент
original_text · context_text · reply_to_message_id
Примеры сообщений из групп
Типичные сообщения с признаками намерения: вопросы про ипотеку, условия покупки, рассмотрение вариантов.

Manual validation
Сравнение оценки парсера с реальной ценностью лида после проверки нейросетью. Позволяет находить ошибки классификации и улучшать правила.
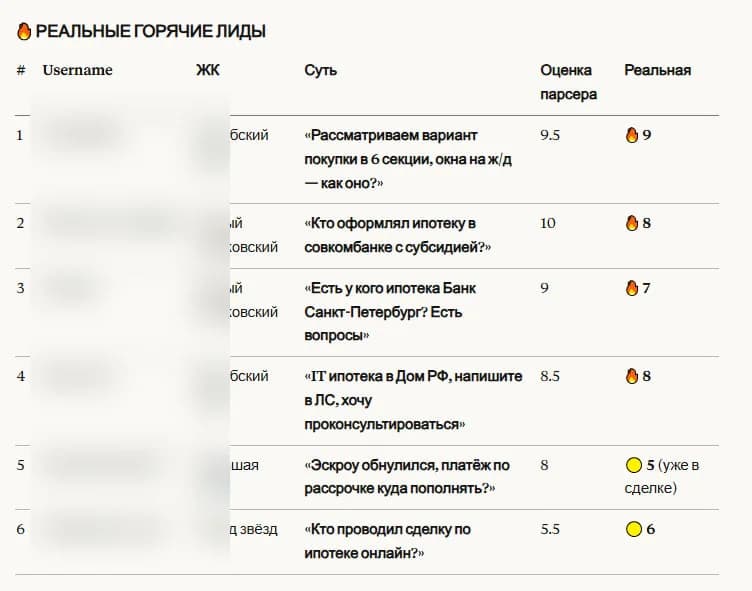
Выводы: часть «hot» — мусор из-за сарказма/контекста → добавлены фильтры. «Late-stage» (уже купили) → отдельная категория.
Human-in-the-loop interaction
Нейтральное консультативное общение без давления. Парсер используется как фильтр, а не как инструмент спама.
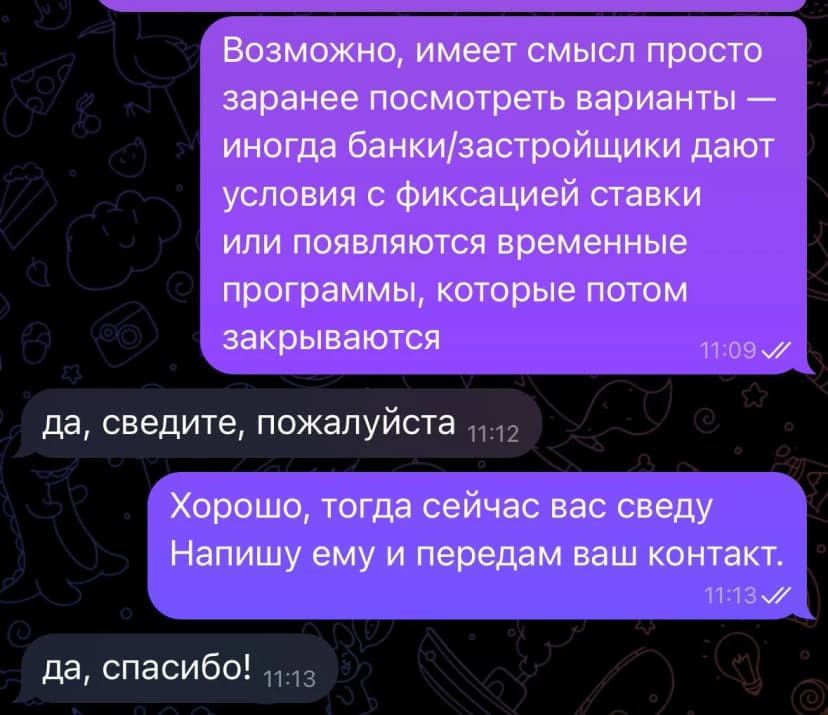
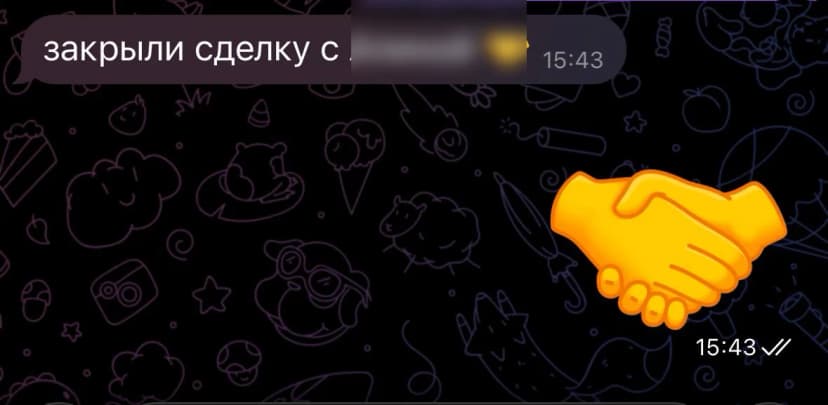
Outcome example
Один из кейсов, где ранний сигнал и корректный контакт привели к сделке. Qualitative proof, не гарантия результата.
Ограничения v1
What's next
Подключение LLM-слоя для:
Цель: weekly отчёт для риелтора в один клик.
Key engineering decisions
UTC normalisation
Все timestamps приводятся к UTC для консистентности между источниками
Dedup keys
Уникальность по chat_id + message_id исключает дубли при повторных прогонах
Context extraction
Извлечение reply-цепочек для понимания контекста сообщения